알고리즘 문제를 풀다 보면, 노드와 간선이 주어지고 가장 짧은 길 찾기 등과 같은 문제들을 자주 볼 수 있다.
이러한 문제를 해결하기 위한 알고리즘이 바로 최단 경로이다.
최단 경로를 구하는 방식은 다익스트라, 벨만 포드, 플로이드 와샬, SPFA로 크게 4가지 정도가 있다.
이전에 플로이드 와샬에 대해 정리한 적이 있으니, 오늘은 다익스트라에 대해 정리해보자.
다익스트라 알고리즘이란?
여러 개의 노드와 간선이 있을 때, 특정한 지점에서 출발하여 다른 노드로 가는 각각의 최단 경로를 구해주는 알고리즘이다. 다익스트라는 기본적으로 매번 가장 비용이 적은 노드를 선택해서 임의의 과정을 반복하기 떄문에 그리디 알고리즘으로도 분리된다. 이 설명은 뒤에 더 보겠다.
다익스트라 알고리즘 원리
다익스트라 알고리즘은 최단 경로를 구하는 과정에서 각 노드에 대한 현재까지의 최단 거리 정보를 1차원 리스트에 저장하며 리스트를 갱신해 나간다.
매번 현재 처리하고 있는 노드와 인접한 노드로 도달하는 더 짧은 경로를 찾으면, 더 짧은 경로로 계속 갱신하는 과정을 거친다.
코드 구현
1. 출발 노드를 시작으로 하여, 출발 노드와 주변에 노드들까지의 거리를 1차원 배열에 갱신해준다.
2. 그 중 가장 짧은 간선을 선택하여 해당 노드로 이동해, 그 노드를 기준으로 주변 간선들과 1차원 배열에 값들과 비교해 갱신한다.
이 과정을 반복하여 출발지점으로 부터 모든 노드까지의 최단 거리를 구할 수 있다.
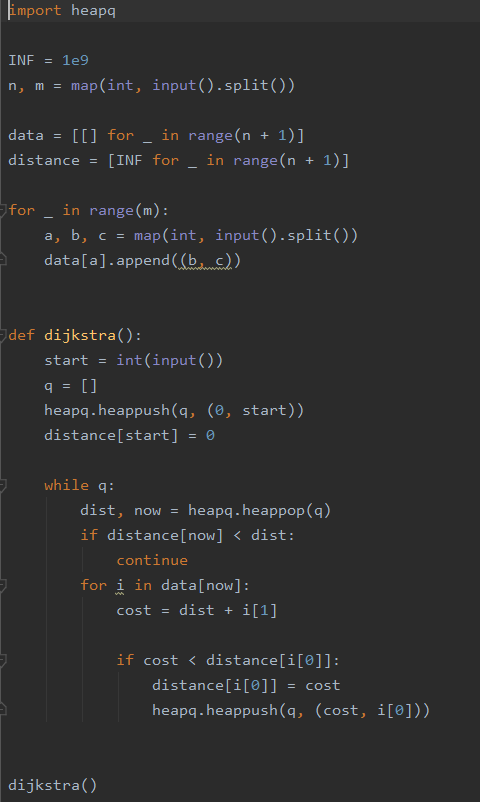
해석: distance는 출발 노드를 기준으로 각 노드까지의 거리가 저장되어 있는 1차원 리스트이다.
q는 출발 노드를 기준으로 각 노드까지의 거리와, 노드가 저장되어 있는 우선순위 큐 리스트이다.
궁금증 해결
+ 여기서 우선순위 큐는 어떤 역할로 쓰이는가?
-> 출발 노드로 시작하여 각 노드까지의 거리를 q에 저장해준다. 그 후, 현재 q리스트에 있는 정보들 중 가장 짧은 거리의 노드를 선택하여 탐색하기 때문이다.
그럼 왜 굳이 가장 짧은 노드부터 탐색해야 하지?
정답은 결론적으로 말해 최소거리 값 갱신 횟수의 증가 때문이다.
언뜻 생각했을 때, 그냥 큐로도 구현하여 모든 경우의 수를 파악해줘도 될 것 같지만
큐와 우선순위 큐를 사용했을 때 나오는 시간복잡도 차이가 상당하다.
일반 큐는 O(E+V^2) 우선순위 큐는 O(ElogV)이다.
일반 큐는 별 다른 기준 없이, 갱신을 하기 때문에 최소거리가 갱신되는 상황이 많이 발생한다.
하지만 우선 순위 큐는 이전에 계산해둔 값이 그 단계에서 최소값이라는 것이 보장되기 떄문에 갱신 횟수가 현저히 줄어든다.
왜 우선순위 큐를 써야만 하나?

만약 그림과 같은 상태에서 1을 출발점으로 하여, 모든 지점까지의 최단 거리를 알아보겠다.
이때 우선순위 큐가 아니라, 큐를 사용하게 된다면 어떻게 될까?
우선 3까지의 최단 거리를 구하는 방법 먼저 보겠다.
6, 3을 큐에 넣은 후, 순서에 따라 연산을 처리할 것이다.
6을 처음 pop한 후, 최단 거리 리스트에 index 3에는 6으로 초기화 해 줄 것이다.
그리고 3 -> 1을 pop한 후 연산을 취했을 때, 또 한번 최단 거리 리스트 index 3에 초기화를 해줄 것이다.
근데 만약 이 과정을 우선순위 큐를 활용하여, push를 해줄 때 거리가 최단 거리인 순으로 넣어준다면 그 연산 횟수는 현저히 줄어들 것이다.
'개발 > 알고리즘' 카테고리의 다른 글
| [알고리즘] 크루스칼 (0) | 2021.03.30 |
|---|---|
| [알고리즘] 유니온 파인드(Union-Find) (0) | 2021.03.29 |
| [알고리즘] 플로이드-워셜 (0) | 2021.03.25 |
| 정렬 알고리즘 (0) | 2021.03.13 |
| dfs로 조합 구하기 (0) | 2021.03.09 |


