우선순위 큐란?
우선 순위를 가진 항목들을 push하고, 우선 순위에 따라 pop하는 자료구조이다.
큐라고 하니 내가 아는 일직선의 큐 형태를 떠올리지만, 그것과는 전혀 다른 트리 형태의 힙 자료구조로 구현된다.
(그래서 우선순위 큐와 힙을 동의어로도 많이 쓴다고 한다.)
힙이란?
힙은 완전 이진트리의 형태로 우선 순위에 따라 push, pop되는 자료구조이다.
크게 최대 힙, 최소 힙 두 가지 종류가 있다.
최대 힙이란?
말 그대로 힙 데이터 요소의 우선 순위가 큰 값으로 이루어져 있는 완전 이진트리이다.
최대 힙의 삽입 방식
1. 완전 이진트리를 유지하며 순차적으로 삽입된다.
2. 삽입 이후에 루트 노드까지 순차적으로 값을 비교하며, 값이 부모보다 크다면 현재 노드와 교체한다.


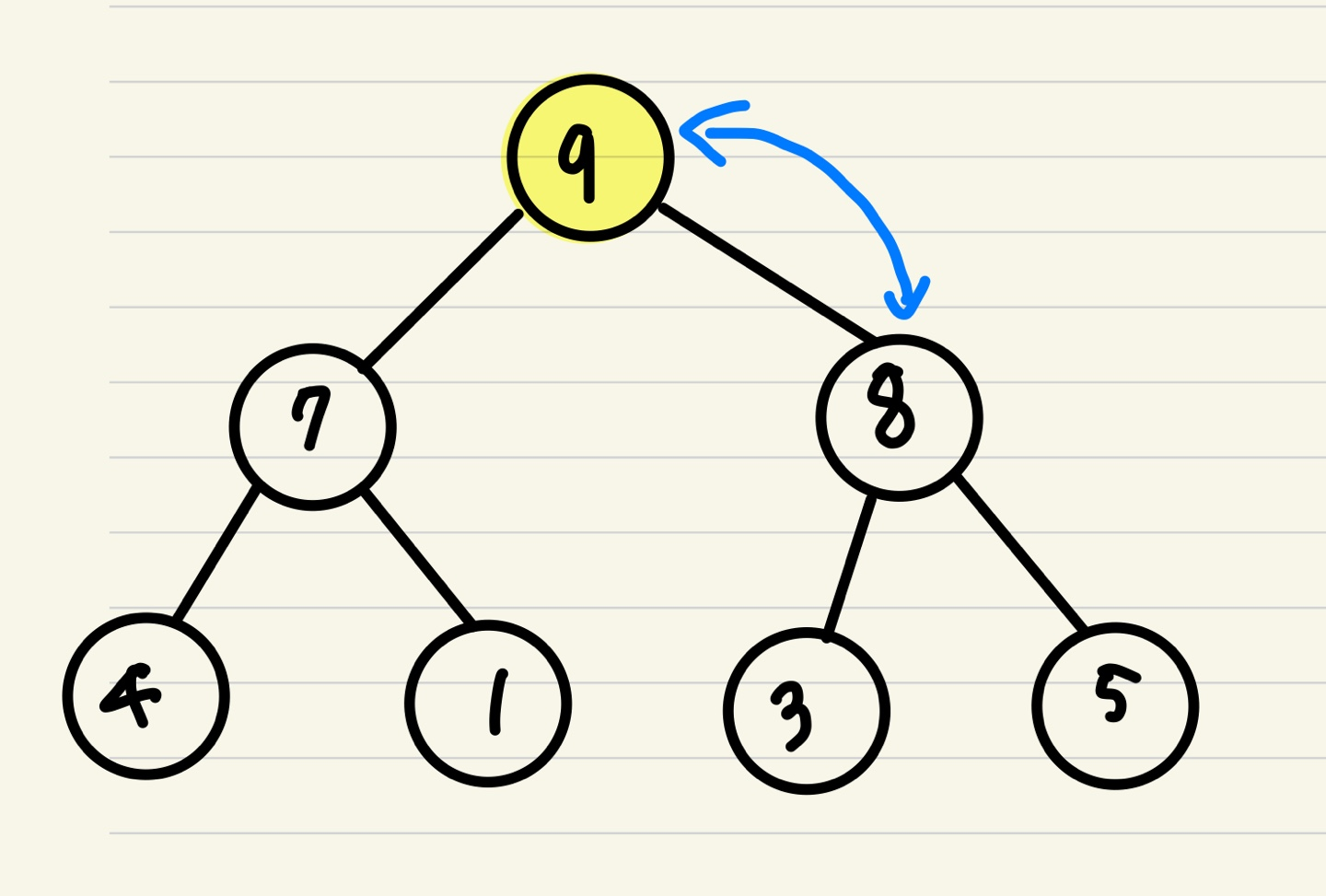
최대 힙의 삭제 방식
1. 루트 노드의 데이터를 pop한다.
2. 맨 마지막 노드가 루트노드로 올라온다.
3. 자식 노드들과 비교하며 자신보다 큰 값 중, 가장 큰 값과 교체한다.
4. 3을 자식 노드가 자신보다 큰 값이 없어질 때까지 반복한다.



파이썬에서 최소 힙 사용방법
파이썬에서는 최소 힙를 쉽게 구현하기 위해 heapq라는 내장 모듈이 제공된다.
삽입 방법
배열에 heapq.heappush를 사용해 우선 순위 큐를 생성하고, 데이터를 삽입할 수 있다.
data = []
heapq.heappush(data, (2, "data1"))은 data배열에 (2, "data1")튜플을 삽입하는 것을 의미한다.
이때 튜플의 첫 번째 인자 값이 우선 순위 값이고, 두 번째 인자 값이 삽입할 데이터 값이 된다.
추출 방법
데이터 추출 방법은 heapq.heappop을 사용하면 된다. 꺼내는 작업의 시간 복잡도는 O(log n)이다.
pop_data = heapq.heappop(data)를 하면 pop_data에는 (2, "data1")의 값이 추출되어 저장된다.
기존의 배열을 힙 정렬로 만드는 방법
애초에 힙 정렬을 만들어 삽입하는 방법도 있지만, 기존의 배열을 힙 정렬로 만드는 방법도 있다.
위의 방법으로 힙을 만들면 시간 복잡도는 O( n * log n )이지만, 지금 소개하는 방법의 시간 복잡도는 O(n)이다.
data = [ (1, "data1"), (2, "data2"), (3, "data3), (4, "data4) ]
heapq.heapify(data) -> 이것을 통해 기존의 배열을 힙 정렬로 만들 수가 있다.
파이썬에서 최대 힙 사용방법
파이썬 모듈의 heapq는 최소 힙 밖에 지원하지 않는다.
때문에 최소 힙을 최대 힙처럼 사용하는 방법 밖에 없다.
기존의 최소 힙의 우선 순위 키 값을 음수로 변환하는 것이다.(그렇게 된다면 우선순위가 역순으로 바뀌기 때문이다.)
'개발 > 알고리즘' 카테고리의 다른 글
| 정렬 알고리즘 (0) | 2021.03.13 |
|---|---|
| dfs로 조합 구하기 (0) | 2021.03.09 |
| [BOJ] 뒤집기_1439 (0) | 2021.03.04 |
| [이코테] 모험가 길드 (0) | 2021.03.04 |
| 2020 KAKAO BLIND RECRUITMENT_자물쇠와 열쇠 (0) | 2021.02.26 |

